Plan 3×, Build Once: How Three Models Plan What One Model Ships

I asked Opus 4.7 and GPT-5.5 to independently plan the same new feature. Then I handed both plans to Gemini 3.1 Pro and asked it to pick the winning combination. Here is the sentence that earned the work:
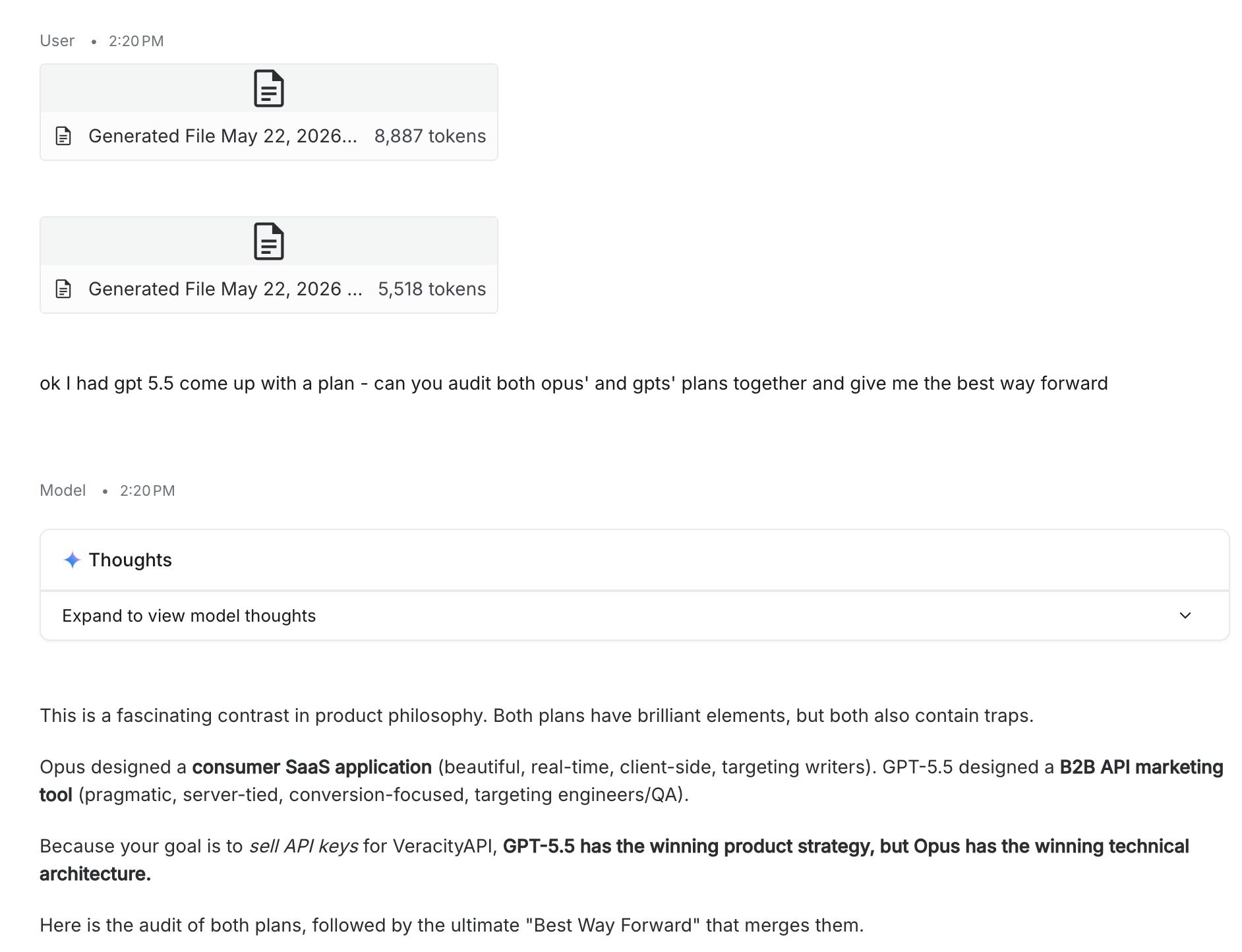
Opus designed a consumer SaaS application (beautiful, real-time, client-side, targeting writers). GPT-5.5 designed a B2B API marketing tool (pragmatic, server-tied, conversion-focused, targeting engineers/QA). Because your goal is to sell API keys for VeracityAPI, GPT-5.5 has the winning product strategy, but Opus has the winning technical architecture.
Each model produced a half-right plan. Single-model planning would have shipped one of them. Gemini's audit produced a synthesis neither model would have written alone.
For every meaningfully complex build, I plan in three models. Opus 4.7 plans it. GPT-5.5 plans it. Gemini 3.1 Pro audits both and picks the Goldilocks. Then GPT-5.5 one-shots the implementation against the reconciled plan.
- The 3-model loop has shipped three one-shot builds so far: the Veracity Chrome extension, the Palmaura backend, and now the VeracityAPI Text Linter.
- The receipts: Opus over-indexes on architecture for the wrong audience. GPT-5.5 over-indexes on conversion with the wrong technical primitives. Gemini reliably picks the half each model got right.
- Three planning passes cost ~$2–4 in API. The implementation pass they save costs ~$20–60. The math is straightforward once you've run it.
This isn't a science. It's three builds. But the pattern is sharp enough that I now refuse to single-model-plan anything bigger than a weekend project.
The loop
For every meaningfully complex build, I run this:
- Opus 4.7 plans it. Fresh context. The plan tends to optimize for architectural elegance and developer experience.
- GPT-5.5 plans it. Fresh context. The plan tends to optimize for product strategy and conversion.
- Gemini 3.1 Pro audits both. Picks the winning combination. Flags what each model missed. Patches the synthesis.
Then GPT-5.5 one-shots the implementation against the Gemini-reconciled plan, stepping through the milestones with subagent-driven development.
The first time I tried this I was skeptical. Three planning passes felt like overhead. By the third build I stopped feeling silly. The Goldilocks plan is the artifact I needed all along.
The receipt: VeracityAPI Text Linter
I'm shipping a new feature on VeracityAPI — an AI text linter at /tools/style-editor. The decision tree was loaded:
- UX: Hemingway-style editor? Static form? Agent skill suite published to GitHub?
- Deployment: Cloudflare Worker only? Open-source repo? Both?
- Architecture:
contenteditable? Textarea overlay? No editor at all — just JSON? - Positioning: Writers? Developers? Enterprise trust teams?
Each model anchored on its own priors. Here is what they each produced.
What Opus 4.7 proposed
Opus produced two framings (I gave it two passes with different lead-in prompts):
Plan A — open-source agent skill suite. Publish to GitHub as veracityapi/ai-text-risk-skills. Five skills: ensemble detector, author-style-compare, provenance-probe, source-claim-audit, benchmark harness. Heavy emphasis on multi-signal risk reports, "evidence not accusations." Local model execution. BYOK for search providers.
Plan B — Hemingway-style editor. Live editor at /tools/style-editor. contenteditable + overlay <mark> spans. Pure-TS calculator shared between browser bundle and Worker. Targets "Hemingway alternative" SEO. Sample text on first load, sidebar with metrics + verdicts.
Both Opus plans were beautifully architected. Both were also positioned for the wrong buyer.
What GPT-5.5 proposed
One plan, sharply different:
- "Veracity Editor" at
/editor— linter positioning, not Hemingway clone - Textarea + mirrored highlight overlay (no
contenteditable) - Fast Scan (deterministic, local) + Deep Scan (LLM-backed, paid) as the conversion bridge
- Authenticated
/v1/analyze-styleendpoint matching existing API patterns - Privacy defaults:
store_content=false, no text leaves the browser on Fast Scan - VeracityAPI action spine:
allow / revise / human_review / reject
GPT got the buyer right. It also picked some questionable technical primitives and skipped the architecture work entirely.
What Gemini 3.1 Pro said
I handed all three plans to Gemini and asked it to audit cold. The synthesis headline was the quote at the top of this post:
Then I asked Gemini to break down what each model got specifically right and wrong. The detail on GPT-5.5 alone was sharp:
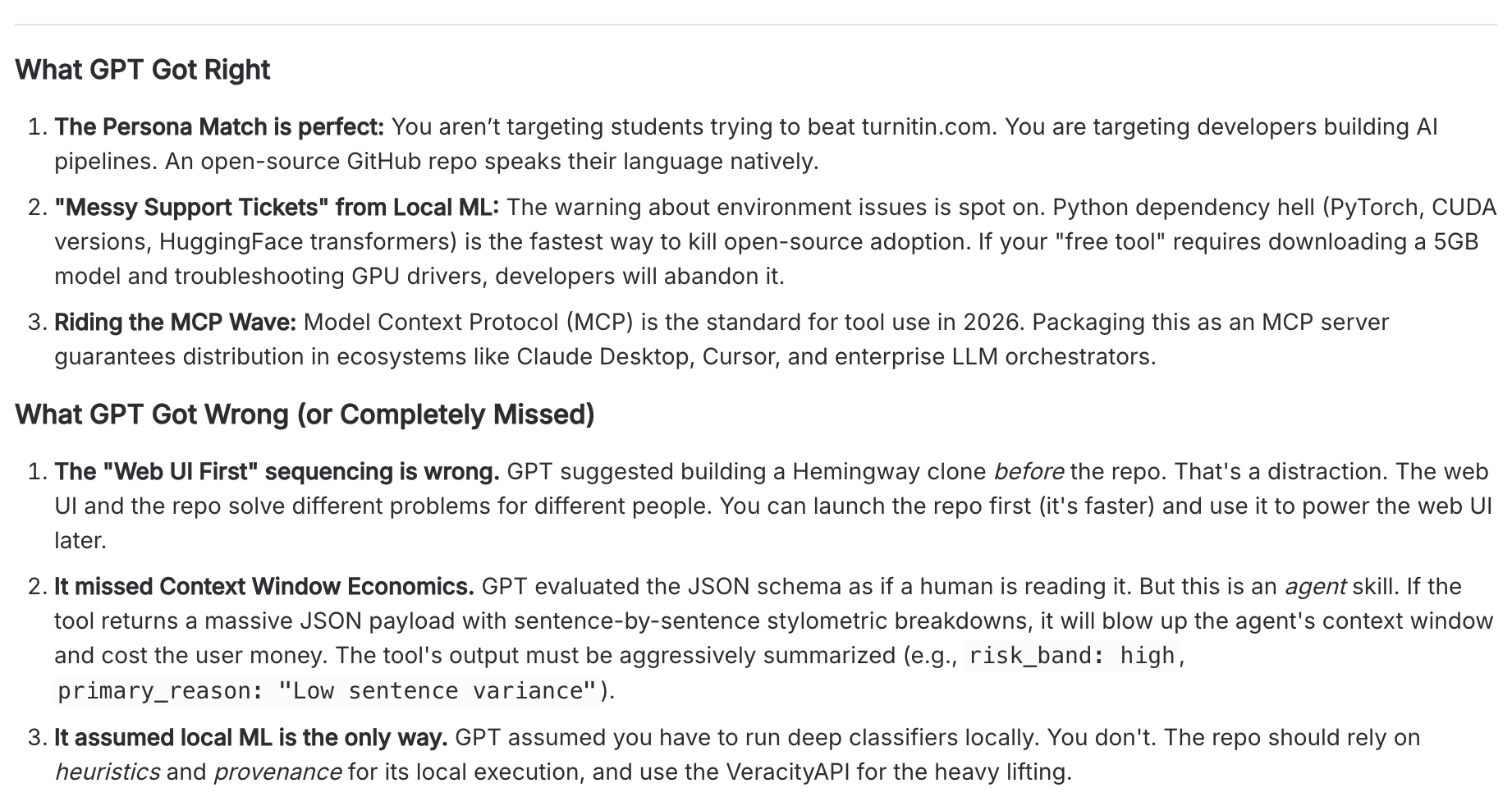
What GPT-5.5 got right:
- Persona match. We are selling API keys to developers building AI pipelines, not students trying to beat
turnitin.com. An open-source GitHub repo speaks their language natively. - "Messy support tickets" from local ML. Python dependency hell (PyTorch, CUDA versions, HuggingFace transformers) is the fastest way to kill open-source adoption. If your "free tool" requires downloading a 5GB model and troubleshooting GPU drivers, developers will abandon it.
- Riding the MCP wave. Model Context Protocol is the standard for tool use in 2026. Packaging this as an MCP server guarantees distribution in Claude Desktop, Cursor, and enterprise LLM orchestrators.
What GPT-5.5 got wrong:
- The "web UI first" sequencing. GPT suggested building the Hemingway clone before the repo. The web UI and the repo solve different problems for different people. The repo can launch first (it's faster) and power the web UI later.
- Missed context window economics. GPT evaluated the JSON schema as if a human were reading it. But this is an agent skill. If the tool returns a massive JSON payload with sentence-by-sentence stylometric breakdowns, it blows up the agent's context window and costs the user money. The tool's output must be aggressively summarized (e.g.
risk_band: "high", primary_reason: "Low sentence variance"). - Assumed local ML is the only way. GPT assumed you have to run deep classifiers locally. You don't. The repo should rely on heuristics and provenance for its local execution and use VeracityAPI for the heavy lifting.
What Opus got right:
- Pure TypeScript analyzer imported by browser and Worker — the isomorphic architecture is the whole technical thesis
- Browser-side Fast Scan, which prevents viral free-tool traffic from burning Worker CPU/D1/model budget
- MCP tool using the same analyzer module
/tools/style-editoras the canonical URL — better SEO/tool taxonomy than bare/editor
What Opus got wrong:
contenteditableeditor — browser selection/input/offset hell. Textarea overlay ships faster and breaks less.- Consumer "Hemingway alternative" persona — writers and novelists do not buy VeracityAPI keys
- Full write-mode/local writing app ergonomics — scope creep. This is an inspector, not a writing environment.
- Public no-auth JSON endpoint as primary distribution — not needed when the browser has the pure TS analyzer
The Goldilocks plan
Gemini's reconciliation:
- Architecture (from Opus): Pure TS analyzer shared between browser bundle and Worker. Browser-side Fast Scan. MCP tool importing the same module.
- Product strategy (from GPT-5.5): Linter/inspector positioning. Textarea + mirrored overlay (not
contenteditable). Fast vs Deep Scan upsell. VeracityAPI action spine. Privacy defaults. - Gemini's correction: Don't claim "open-sourced" until the analyzer module actually ships in a public package. Use "transparent heuristics" until then.
The output is a 25-section implementation plan that reads like neither Opus nor GPT-5.5 would have written alone. It is sharper than either input. That is the whole point.
The one-shot
The Goldilocks plan goes to GPT-5.5 as the implementer. We step through the milestones with subagent-driven development — the plan itself is the spec.
For the text linter, that is 14 milestones from shared analyzer contracts → parser → dictionaries → metrics → scoring → browser bundle → public page → validation → endpoint → conversion path → MCP → docs → eval harness → feedback.
This is the third complex build we've shipped through the same loop:
- Veracity Chrome extension. Clean one-shot. The Opus plan wanted a popup; Gemini called the side panel for context-window economics. The build worked on first deploy.
- Palmaura backend. Clean one-shot. The iOS app side had more hiccups — Swift, Xcode, and App Store review introduce variance that doesn't exist in Cloudflare Workers — but the planning workflow itself held.
- VeracityAPI Text Linter. Currently in milestone 1 with GPT-5.5. (If you're reading this and the editor isn't live yet, check back.)
Why three, not two
Each model has predictable blindspots when I ask it to plan alone:
- Opus 4.7 over-indexes on architecture. It will design beautiful, defensible technical systems for the wrong audience.
- GPT-5.5 over-indexes on conversion. It will design pragmatic B2B flows but pick the wrong technical primitives.
- Gemini 3.1 Pro is the best auditor I've found at picking the winning combination. It is not as creative as a primary planner, but it consistently says “you adopted X from Opus and Y from GPT, here's what neither caught.”
Two-model planning misses the audit step. You can ask Opus to audit GPT, or vice versa, but they tend to defend their own framing's underlying choices. Gemini comes in cold and rules.
The economic argument
Three planning passes is expensive. Each plan is 5,000–9,000 tokens of input plus a similar amount of output. The Gemini audit on top is another 3,000–5,000.
That is maybe $2–$4 in API costs per planning loop.
The implementation that follows is also expensive — typically 50,000–200,000 tokens for a meaningful feature, $20–$60 in API costs.
If single-model planning produces a plan that ships, then a follow-up build to fix what was missed, that's two implementation passes. $40–$120.
The 3× planning loop has cost us one implementation pass in every build it has run on. The math is straightforward: $2–$4 of extra planning saves $20–$60 of re-implementation. The harder-to-quantify saving is that the first version actually works.
What this isn't
A few honesty flags:
- This is not a science. Three builds. Three different domains (Chrome extension, mobile backend, hosted SaaS feature). The workflow has held for those three. It might not generalize past a sample size of three.
- The model assignments will drift. Opus 4.7 won't be the architecture-priming planner in six months. GPT-5.5 won't be the conversion-priming planner. The personas attach to model versions, and model versions ship. Re-audit your model assignments quarterly.
- Gemini's audits are not always right. On one earlier build (not described here), Gemini picked Opus's UX framing when GPT's would have been better. I caught it on review. The audit is a strong signal, not gospel.
- The "one-shot" framing is generous. What we actually mean is: the first implementation pass produces code that compiles, runs, and passes the milestones' acceptance tests. There are always edits during code review. But there is no "this plan was wrong, restart the build" moment.
The takeaway
Single-model planning ships one model's blindspots.
Three-model planning surfaces them — and the audit picks the synthesis neither model would have produced alone.
The first time you do this, you'll feel silly running three plans for what feels like a one-model task. After the third build, you stop feeling silly. The Goldilocks plan is the artifact you needed all along.
— Bernard
Newsletter
Get the next post by email.
One email when I publish something new. No spam, no fixed schedule, unsubscribe anytime.