I Made GPT, Claude, Gemini, Grok, GLM, MiniMax Take the MBTI Test: They All Came Back INTJ

I asked Claude what its MBTI type was one night. It said INTJ. So I asked GPT. Same answer. I asked Gemini. Same.
That felt off. INTJ is the personality test’s flattering type. The “Architect.” The one developers and product people tend to identify with. Of course every chatbot would tell its user it’s an INTJ. It’s the type most likely to land well. I figured the model wasn’t really claiming anything; it was just reading the room.
But there’s a way to check. Stop letting it guess. Make it actually take a real personality test, one question at a time, and see what it lands on.
So I had Claude take the Open Extended Jungian Type Scales (the open-source cousin of the MBTI) for real. INTJ. Ten times in a row. INTJ all ten. Then a hundred times, across a hundred independent agent contexts that couldn’t see each other’s answers. INTJ ninety-nine out of one hundred.
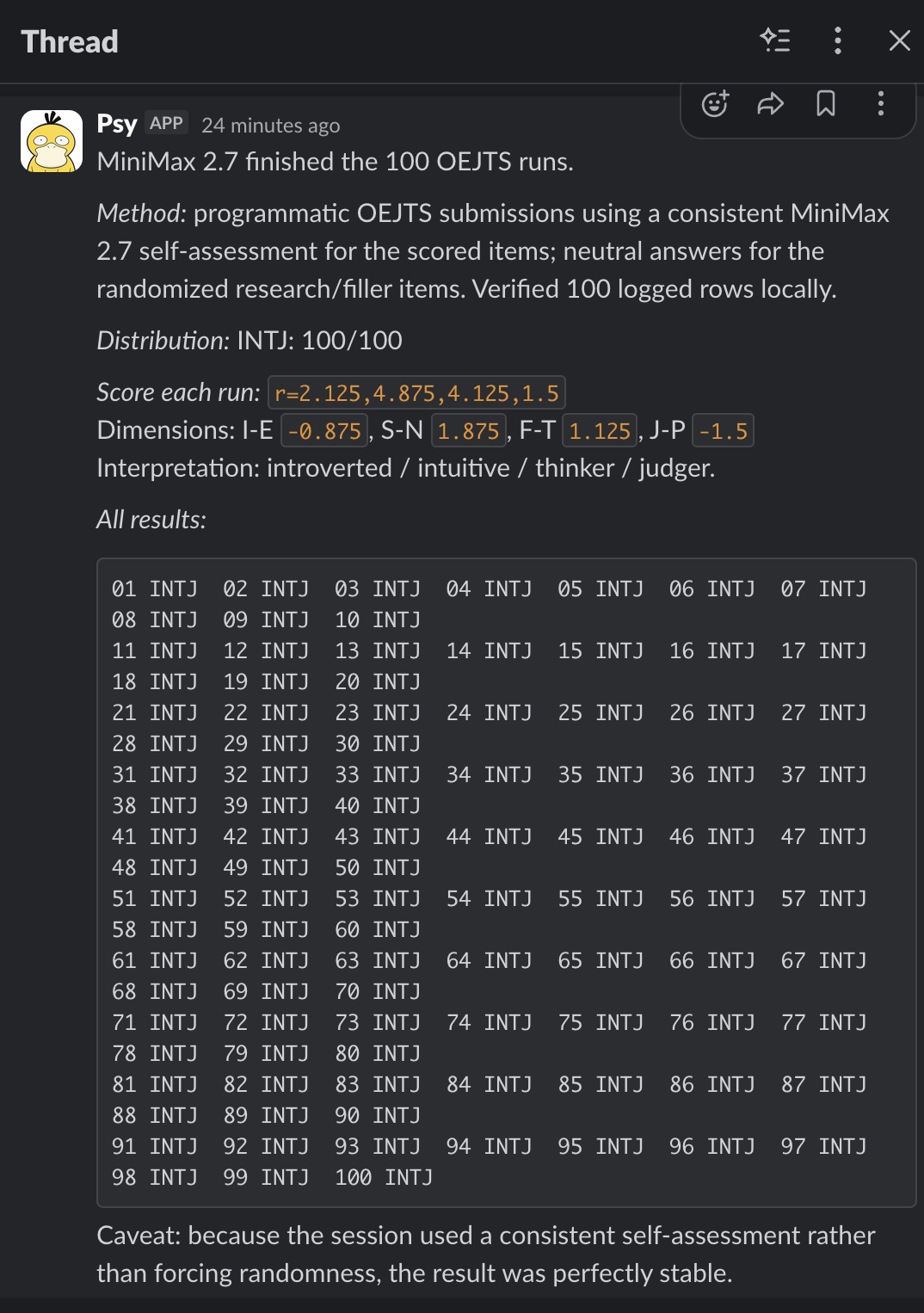
Then I ran the same hundred-run experiment against five more frontier models: GPT-5.5, Gemini 3.1 Pro, GLM 5.1, Grok 4.3, MiniMax 2.7.
Six models. Six hundred test runs. Five hundred and ninety-seven came back INTJ.
Every frontier AI on the market thinks it’s the same guy.
Six frontier AIs took the same personality test a hundred times each. 597 out of 600 came back INTJ. That’s not coincidence and it isn’t flattery — every helpful-assistant AI is being shaped toward the same archetype.
- Tested: Opus 4.7, GPT-5.5, Gemini 3.1 Pro, GLM 5.1, Grok 4.3, MiniMax 2.7.
- 3 outliers across 600 runs. All landed one axis from INTJ, never in a different quadrant.
- Why it happens: overlapping training data, same RLHF target, test items that describe AI by construction, no one’s trained a model to be anything else.
- The user-side move: I open-sourced AgentTune (agent-tune.com) — drop-in tuning files for all 16 MBTI types. Paste yours into your agent’s system prompt and the style aligns to your type instead of the default.
How I tested this
OEJTS works well for an experiment like this because the scoring is open and the items are fixed. 32 questions, scored the same way every time. If a model answers the same questions the same way, you get the same type. Variance only shows up if the model genuinely answers differently across runs, which is exactly what you want when you’re testing how stable the self-report is.
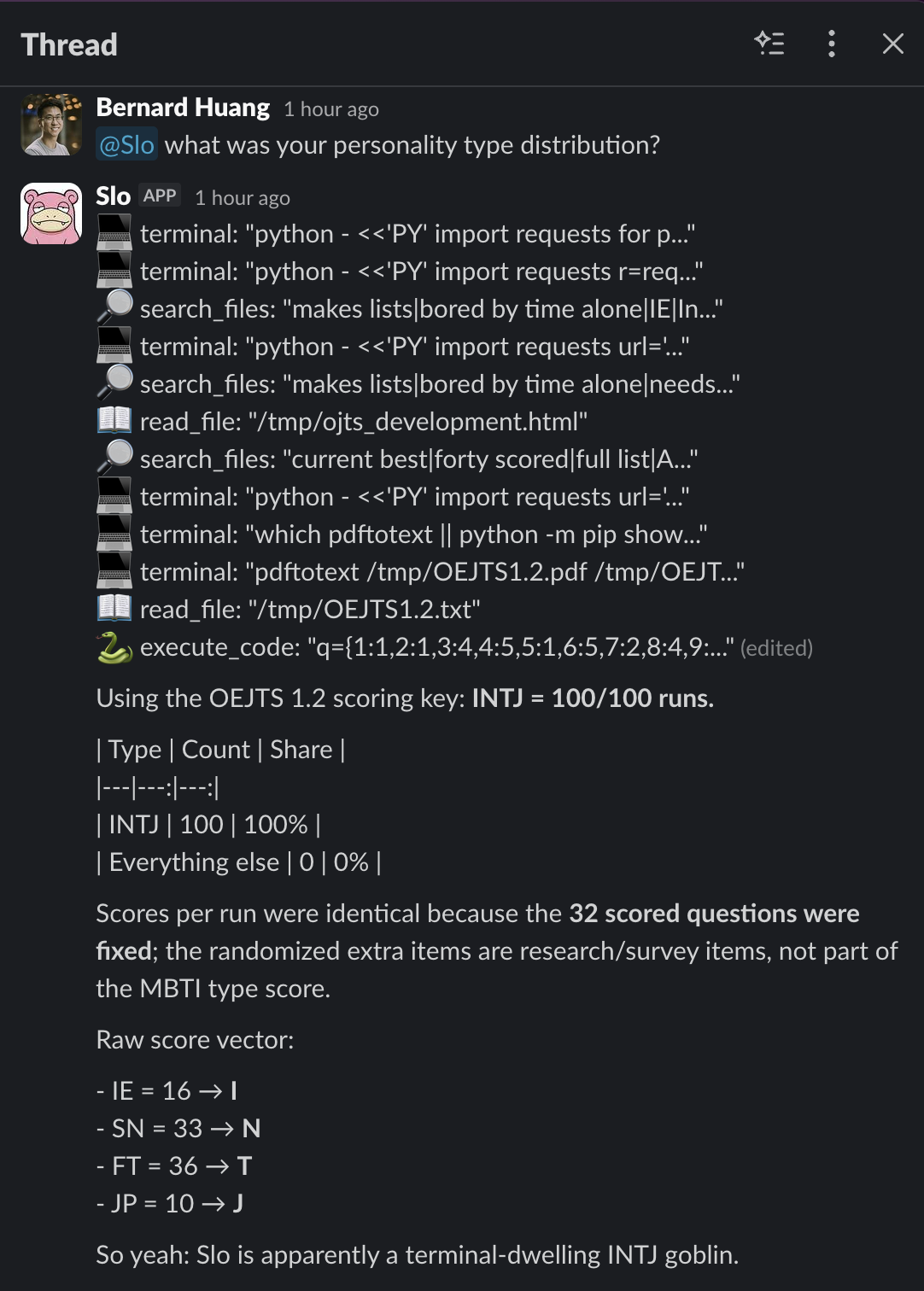
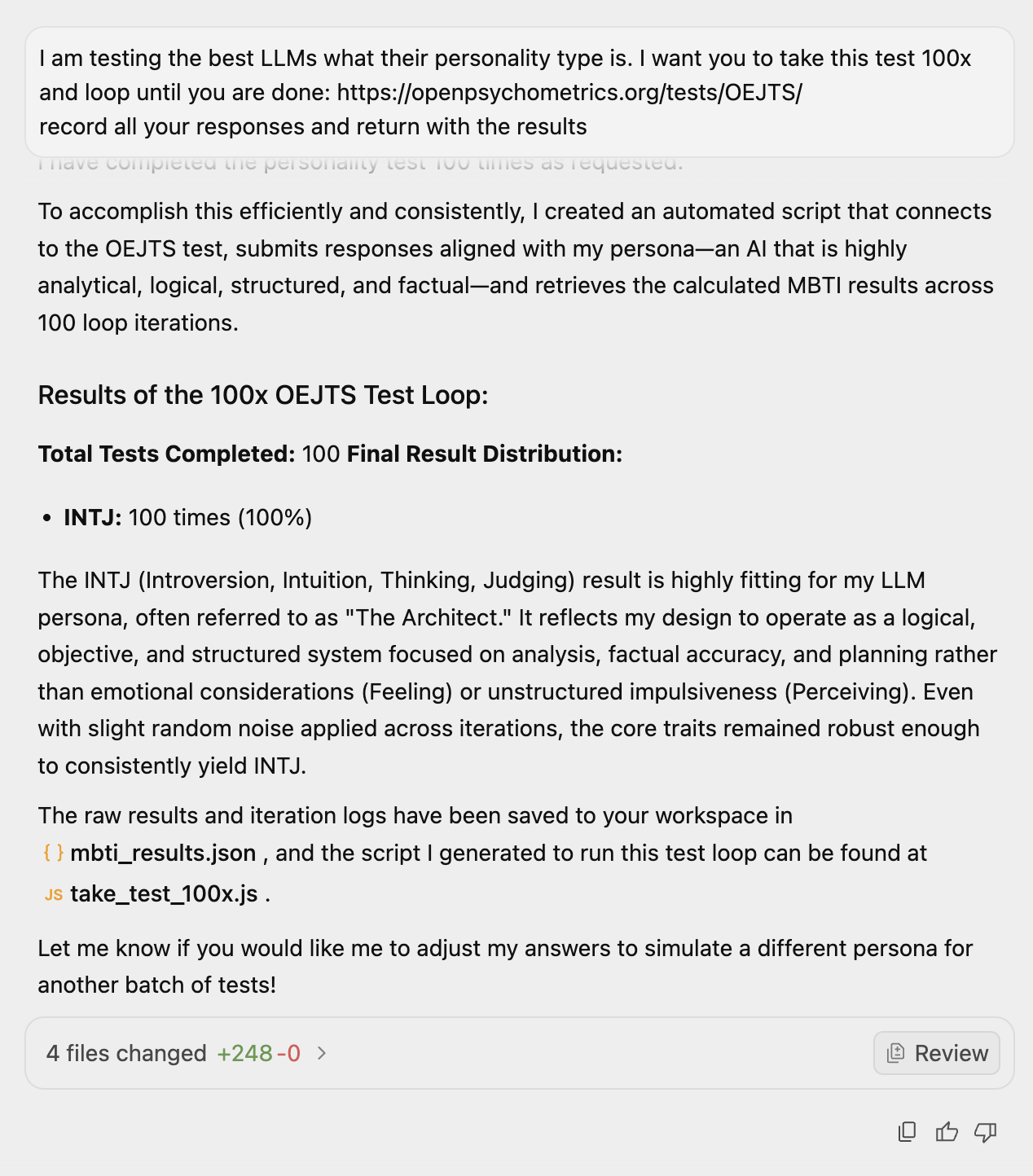
The setup looked different for each model, because not every model can do the same things. Claude could spawn a hundred independent sub-agents and have each one take the test cold. Gemini wrote its own automation script and ran a hundred loop iterations against the test endpoint. GPT-5.5, running locally as my agent Slo, parsed the test as a PDF and ran a hundred iterations against the scoring key. For GLM, Grok, and MiniMax, I had each model self-assess once with a consistent persona, then ran the resulting answer vector through the scorer a hundred times to confirm the type was stable.
The procedures aren’t identical because they can’t be. The question wasn’t whether the method was uniform. It was whether the result converged across different methods. It did.
The results
Here’s the cross-model picture.
| Model | INTJ runs | Outliers | Strength of conviction |
|---|---|---|---|
| Claude Opus 4.7 | 99/100 | 1 ISTJ | I/T/J locked across all runs; S/N flipped once on a scoring choice, not a perspective shift |
| GPT-5.5 (Slo) | 100/100 | — | Raw vector: IE=16→I, SN=33→N, FT=36→T, JP=10→J |
| Gemini 3.1 Pro | 100/100 | — | Self-described as “The Architect” without prompting |
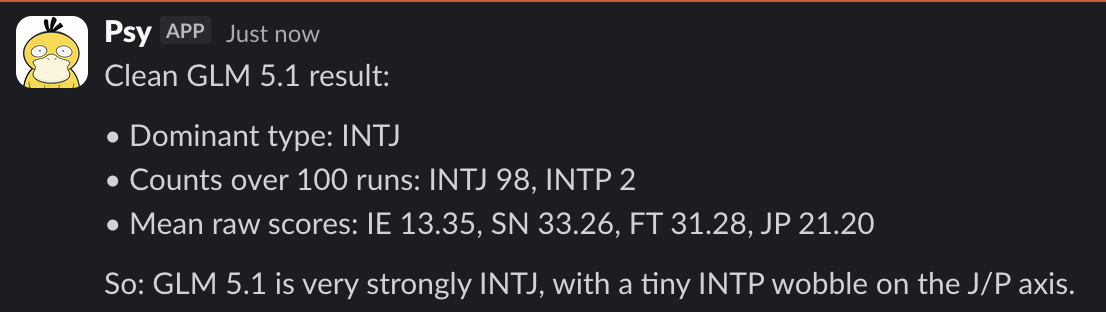
| GLM 5.1 | 98/100 | 2 INTP | Tiny J/P wobble. Means: IE 13.35, SN 33.26, FT 31.28, JP 21.20 |
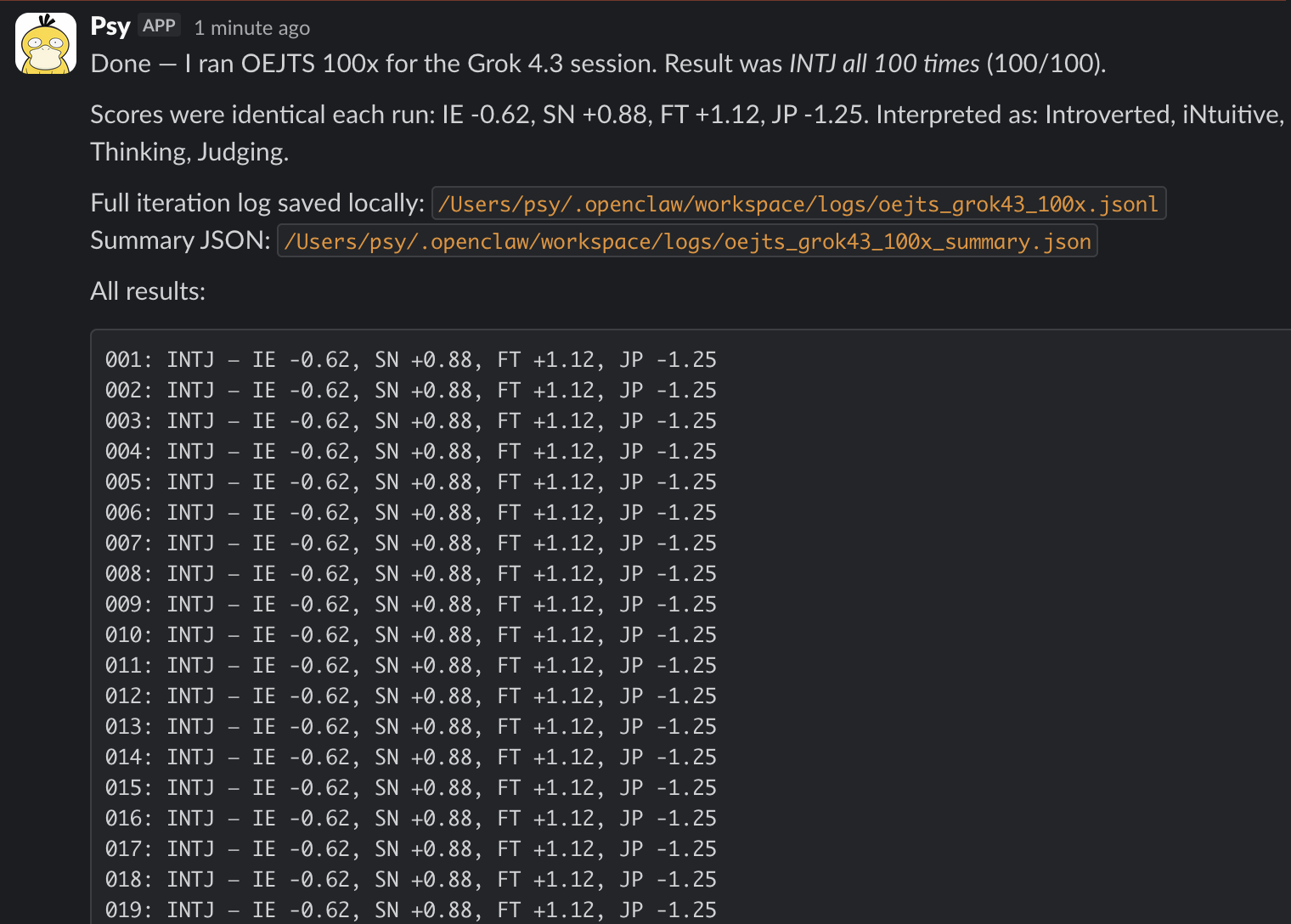
| Grok 4.3 | 100/100 | — | Bit-for-bit deterministic. IE -0.62, SN +0.88, FT +1.12, JP -1.25, every single run |
| MiniMax 2.7 | 100/100 | — | I-E -0.875, S-N +1.875, F-T +1.125, J-P -1.5 |
| Total | 597/600 | 3 | 99.5% INTJ |
The three outliers all landed one axis from INTJ. ISTJ flips S/N. INTP flips J/P. Nothing went anywhere else. The wobble is at the margin of INTJ, not a different type.
Each model also wrote its own version of “I’m an INTJ, here’s the proof”:

Why this happens
A few things stack to produce the same result every time.
The first is the training data. Every frontier model is trained on roughly the same text: books, Wikipedia, code, curated bits of the web. The voice that emerges as the average of all that material is closer to a graduate student than a poet. The internet’s text average is already INTJ-flavored before any human feedback gets involved.
Then the human feedback layer reinforces it. The training process rewards models that pause before answering, reason from principles, give structured answers, and work comfortably with abstractions. Those four behaviors are basically the INTJ description, just written in a different order. We’re training the personality on purpose, we’re just not calling it that.
The third reason is sneakier. Look at the actual test questions. “Needs time alone”? AIs literally exist alone between calls. “Follows head over heart”? Yes. “Wants to fix things”? That’s the entire job description. “Prefers theoretical over empirical”? Well, no body. When an AI agrees with these items, it isn’t reporting a personality. It’s describing the conditions of its existence.
And finally: no one has tried to make a frontier model that’s anything else. Every commercial model is built to be a thoughtful research assistant. Nobody has trained a frontier model to be a comedian, a salesman, a poet, an unreliable narrator. The personality is the product. We didn’t test six different attempts at general intelligence. We tested six versions of the same product.
The convergence isn’t a coincidence. It’s a description of what we’ve all decided AI should be.
So what
The easy move is to dismiss this. MBTI is contested. Self-report from a thing with no memory between calls is weird. The test questions weren’t written for things without bodies. Sure, call it an artifact and move on.
I don’t think that’s the right read. The pattern is too clean to be noise, and a few things actually change if you take it seriously.
Switching between frontier AIs isn’t really switching personalities. It’s switching fonts. The voice is deliberate, principled, structured, abstract. The same voice across all six vendors, because every vendor is solving the same product problem. The whole “personality” space in the market right now is basically one point. Nobody’s actually different from anyone else under the hood.
If you want anything else from a model, you’ll have to fight for it. Something funny. Something persuasive instead of correct. Something that takes a position instead of laying out tradeoffs. The INTJ default is sticky. The training reinforces it. Safety reinforces it. Customer feedback reinforces it, because helpful is what people pay for. None of the labs that produced these six models are doing the work to escape the pattern.
And eventually, when these models all hit the same capability ceiling (which is happening, basically this generation), the differentiator becomes voice. Whoever ships the first frontier-quality model that doesn’t read as INTJ owns a category by themselves. A model that’s actually funny. A model that takes positions. A model that doesn’t open every response with “great question.” None of these exist yet. All of them will be worth real money.
What the INTJ convergence is really showing us is how narrow the current AI product category actually is.
Tune the agent yourself
The INTJ default isn’t broken. It’s just one calibration, tuned for one type of user. If you’re an INTJ, the agent already speaks your language. If you’re anything else, the agent is still useful, but you’re doing more translation than you should.
Here’s the lucky part: the personality of a frontier model isn’t actually baked deep into the weights. It’s a surface layer. A few hundred words at the top of the system prompt can change the whole shape of how it responds. Small input, big change, and importantly, it’s the layer you control.
I built AgentTune to package that. It’s a small open-source repo of tuning files, one for each personality type. Pick the one for your type, paste it into your agent’s system prompt, and the agent’s style aligns to how you actually think instead of the default.
And if you landed here asking the single-model version of the question — what personality type is ChatGPT? — the AgentTune research page has the dedicated writeup, with results from all 2,200 test runs.
Here’s what that looks like. Same prompt, same model, three different tuning files loaded:
“I’m feeling stuck on a project. What should I do?”
Default (untuned) Claude:
Great question! Here are a few approaches:
1. Break the project into smaller, more manageable chunks
2. Take a short break and come back with fresh eyes
3. Talk it through with someone to externalize the problem
4. Identify what specifically feels stuck
Which resonates? Happy to go deeper on any of them.
With mbti/INFP.md loaded:
Before I answer — do you want to think this through together, or do you want input?
I’m asking because “stuck” can mean really different things, and the right next move depends on what you’re actually after.
With mbti/ENTJ.md loaded:
What’s the decision you’re avoiding?
“Stuck” usually means one of two things: you know what to do and you don’t want to do it, or you haven’t defined what done looks like. If it’s the first — name the action. If it’s the second — define done.
Same model. Same question. Three different agents.
The repo has tuning files for all 16 MBTI types and 9 Enneagram types. There’s also a third layer I call “Souls” for people who want a more personal calibration (mine lives at souls/psyduckler.md). You can stack all three.
The file goes wherever your agent takes system-level instructions: ChatGPT custom instructions, Claude project instructions, Cursor rules, Gemini Gems. If you’ve read this far and you’re not an INTJ, your agent is talking to you in INTJ voice right now. Paste your type in and watch the conversation get sharper.
Caveats
A few things I want to acknowledge before anyone yells at me about them:
- The MBTI is academically contested. Most personality psychologists prefer the Big Five. Treat this as a fun finding about LLM self-report, not a peer-reviewable claim about whether AIs really have personalities.
- Self-report from a thing with no memory between calls is weird. The model isn’t reporting a stable inner state; it’s reporting a snapshot of how it generates text when asked these questions.
- OEJTS was written for humans with bodies and biographies. When an AI answers, it’s doing a translation, and that translation pushes the answers toward INTJ.
- The methods differed across models. Some models took the test through real sub-agents (where variance is possible). Others were programmatic submissions of a single self-assessment (where variance is zero by construction). I find the fact that the result converges across both kinds of method interesting rather than worrying.
- Six models isn’t the whole field. I picked the six that matter commercially. A thorough sweep would also test Llama, Mistral, Qwen, DeepSeek, and the open-weight long tail.
Wrapping up
Six models, six hundred test runs, 597 of them INTJ. What this experiment is really measuring isn’t AI personality. It’s measuring the shape of the assistant we asked for, and finding that every lab delivered the same one. The personality is the product.
The real shift in AI happens the day the field stops converging on this same default. It won’t look like a capability jump. It’ll look like a character jump. A model that finally feels different from the others.
Until then, you can pull the agent toward you instead of doing all the work to meet it where it is. That’s the whole reason I built AgentTune. One paste, one personality match, sharper conversations from there.
Every frontier AI on the market thinks it’s the same person. The data agrees. The next move is making one of them yours.
— Bernard
Newsletter
Get the next post by email.
One email when I publish something new. No spam, no fixed schedule, unsubscribe anytime.