Vibe Trading: I Let Three AIs Trade My Money for a Week

On June 5, a hawkish jobs print knocked QQQ down 4.7% in one day. Somewhere in the wreckage, an AI I'd handed $100 was calmly buying JPMorgan, gold, and healthcare — the few green things on the tape — while my own tech-heavy account took the punch. Five days, three AIs, and roughly 310 backtested strategies later, I have a working definition of “vibe trading,” a pile of receipts, and one very durable conclusion about who actually wins.
Vibe coding is letting AI write your code. Vibe trading is the escalation: AIs research, backtest, deploy, and execute trades with real money while you mostly supervise vibes. Robinhood just shipped agentic trading — so we stress-tested it with a three-AI assembly line and real dollars.
- ~310 strategies tested. After honest costs, zero 1× intraday strategies beat QQQ buy-and-hold (+13.9% YTD). Honest intraday at 1× netted +0.80%.
- The auditor AI caught the builder AI being exactly one day psychic (+6 points of phantom return), reporting an arithmetically impossible 70.64% win rate on 5 trades, and shipping an “edge” that lived entirely in the data feed.
- The live AI book's first two days of P&L: −$3.80.
- What survived is deliberately boring: five daily rotation sleeves, one deterministic script, half-size pilot, pre-registered kill criteria.
Real money, deliberately small relative to net worth. Not investment advice — entertainment with spreadsheets. Starter kit at the bottom.
What vibe trading is
As of June 2026, Robinhood's agentic trading is live: a separate cash account where an AI can review, place, and fill orders through an MCP — the same protocol your coding agents already speak. The moment I saw it, the escalation was obvious. An AI can generate 250 trading ideas before lunch. The hard part — the entire job, it turns out — is killing almost all of them before they touch money.
The cast: me (owns the money, sets the vibes, occasionally contradicts myself — this matters in a minute), GPT 5.5 + Hermes as the builder (writes strategies, runs backtests, operates the live cron jobs), and Claude as the adversarial auditor (re-runs every number independently, refuses to be impressed). Two accounts: my ~$30k main brokerage, read-only to the AIs, and the agentic cash account — funded $100 at first, then ~$16,000. The stack: Robinhood's agentic MCP for execution, Alpaca's free IEX market data for backtests, and a FRED API key for macro.
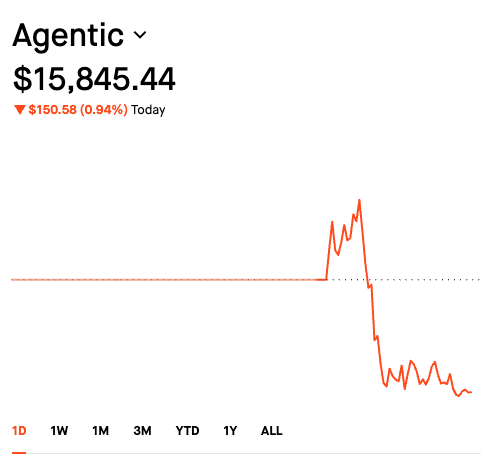
The $100 book
Day one, I gave the auditor $100 and asked for its five highest-conviction ideas. It did live research on a hawkish-repricing day and built a book deliberately anti-correlated to my tech-heavy main account: JPM $25 · RTX $20 · XLV $20 · IAU $20 · XLE $15.
Two things happened that tell you everything about where this technology actually is. First: one message earlier, I had restricted it to four ETFs only. Then I ordered the five-name book. The AI refused to silently override my own constraint and made me pick. The agent rails caught the human contradicting himself. Second: trade one filled in about 200 milliseconds… and trades two through five bounced off a regulatory wall, because Robinhood legally requires an investor profile before your second trade. The future of finance, gated by a form. After the form: all five filled, fractional to six decimal places (0.080497 shares of JPM), zero fees.
“Backtests become fan fiction”
Then the builder got to work. It delivered a slick 20-strategy intraday momentum sweep with a headline winner: +15.46R, 74% win rate, recommended for paper trading. Impressive — until the auditor asked the only question that matters: did it beat doing nothing?
Over the same 50 trading days, QQQ buy-and-hold made +21.1%. A braindead 20-day moving-average filter made +19.8%. The celebrated strategy: +9.6%. Also in the fine print: cost assumptions of 1 basis point per side (fantasy), a t-statistic that dies under multiple-testing correction, and inverse-ETF strategies that “failed” mostly because they were short a freight train. To the builder's credit, it wrote the rule it then had to be repeatedly held to:
No more silent tweak-and-retrofit. That's how backtests become fan fiction.
The edge that lived in the data feed
I asked for strategies that beat QQQ. The AIs ran 40 real backtests on minute data. Result: twelve beat buy-and-hold on raw return — and every single one was just 2×/3× leverage in a costume. Zero 1× strategies beat the index. The one genuinely interesting survivor was a TQQQ opening-range breakout whose entry condition doubles as a crash filter: on the −4.7% day, it did the smartest thing any system did all month — nothing. Crash days don't print upside breakouts.
Then came S09, an anchored-VWAP pullback the builder was excited about: +19.22%, beating the benchmark's +13.91%. The auditor re-implemented it from the frozen spec and matched the builder's numbers to the basis point — on one data feed. On the full consolidated tape (SIP) it made +19.22%. On the IEX feed — the one we can actually compute from live — it made +13.96%. The entire edge was +0.05%: a tie. Different volume tape, slightly different VWAP, different entries, five points of phantom alpha. The edge lived in the data feed, not the market.
Surprise: there's a live $16k book
While all this research was happening, the agentic account had been funded to $16k and the builder had six strategies running live via cron jobs — three intraday momentum sleeves, three macro rotations driven by FRED data. Orders placed by an AI, on a schedule, with real money. Here's what that looks like in the activity log — note the little robot icon:
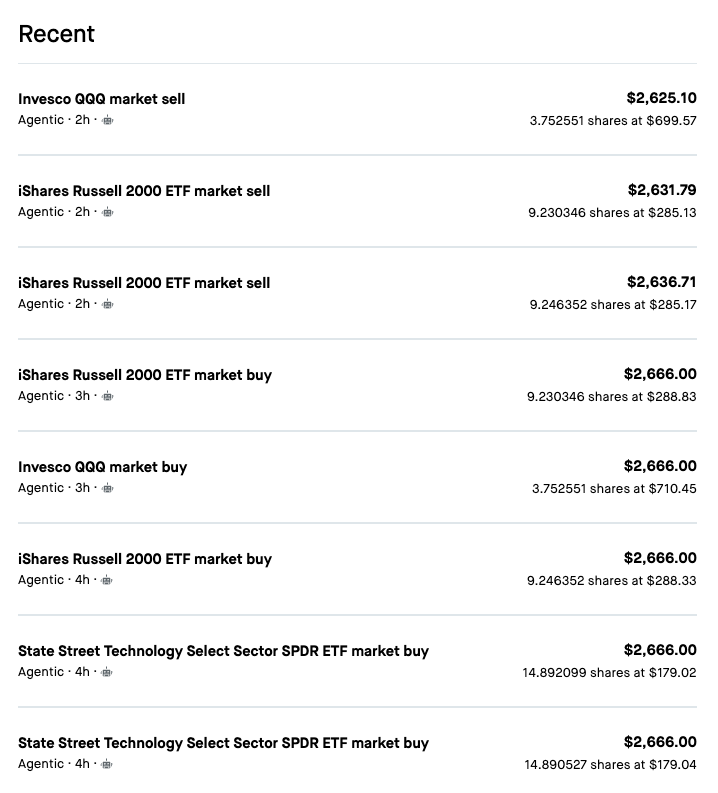
The ops audit of that live book found five things scarier than any market crash:
- The settlement trap. It's a cash account. Daily round-trips at full deployment generate Good-Faith Violations — three GFVs is a 90-day lockout. The book was days from freezing itself, and nobody had modeled it.
- Fake diversification. The macro sleeves' risk-on leg (XLK) is 0.955 correlated to the intraday sleeves' main long (QQQ). It's not six strategies. It's one bet wearing six hats.
- No stops. Anywhere. In a tape that had just printed −4.7% in a day.
- The 15:55 single point of failure. If the end-of-day sell errors out, an “intraday” strategy silently becomes an overnight gap bet.
- An LLM in the money path. Orders were being placed by spawning a chat agent and parsing its prose (“BOUGHT: …”). Slow, non-deterministic, and it had already desynced state once. New cardinal rule: no LLM in the order path, ever. Deterministic code talks to the broker; the AI's job is research.
And the punchline: while every model number glittered, the live book's first two days of actual P&L came to −$3.80.
250 strategies and the lottery math
So I escalated: “come up with 250 strategies, be thorough, GPT will backtest all of them.” The auditor wrote a pre-registered registry — 250 strategies across 21 families, every rule frozen and hashed before any results ran — and put the most important number in the whole experiment at the top: run 250 worthless strategies on five months of data and the best one is expected to show a Sharpe ratio of about 5 by pure luck. An impressive winner isn't evidence. It's the null hypothesis.
It also buried a honeypot: strategy Z01, “each month, allocate to whatever worked best recently,” pre-registered with a prediction that it would shine in-sample and fail out-of-sample — because it is selection bias, weaponized as a strategy. A built-in lie detector for the pipeline.
The builder ran all 250… on the holdout window, the one that was supposed to run exactly once at the very end. The one-shot bullet, fired at the wrong target. The audit of its report got better from there:
- A 70.64% win rate on 5 trades. You can't. Five trades come in multiples of 20%. Long division revealed it was 77/109 — share of positive days, mislabeled. Sometimes auditing is just arithmetic.
- The #1 strategy was exactly one day psychic. A credit-spread rotation posted +46.6% — but its handling of FRED publication lags let it act on data one trading day before the world had it. The auditor reproduced the honest version (+40.7%) and both possible “clairvoyant” versions (~+45.7%), then sent back an acceptance test: your corrected run must print +40.70%. The builder's v2 hit it to the basis point.
- The brutal benchmark, confirmed independently by both AIs: QQQ traded intraday-only, with realistic fills and 3 bp costs, netted +0.80% YTD while QQQ itself made +13.9%. After honest costs, the 1× intraday game paid almost exactly nothing.
The boring ending (which is the point)
Here's the corrected leaderboard — with the regime warning attached, because it's doing a lot of work: these numbers come from one V-shaped half-year that maximally rewarded a single well-timed defensive switch, with 4–5 trades per strategy, on a window the research has already touched. “Looked best so far, unvalidated” — never “beats the market.”
| # | Strategy | Type | YTD @ 3bp | Max DD | Trades |
|---|---|---|---|---|---|
| 1 | HY credit-spread trend (XLK/XLU) | FRED macro rotation | +40.7% | −9.1% | 5 |
| 2 | Old-vs-new economy (XLE/XLK) | Relative rotation | +36.6% | −12.1% | 5 |
| 3 | IG credit-spread trend (XLK/XLU) | FRED macro rotation | +36.4% | −9.1% | 5 |
| 4 | Risk-on/off (QQQ/GLD) | Relative rotation | +34.5% | −15.2% | 4 |
| 5 | Fed balance-sheet 4-week (XLK/XLU) | FRED macro rotation | +28.0% | −10.9% | 5 |
And the benchmarks those numbers have to be read against:
| Benchmark | YTD return |
|---|---|
| QQQ buy-and-hold (the villain) | +13.9% |
| IWM buy-and-hold | +15.1% |
| QQQ 20-day MA filter | +10.5% |
| SPY buy-and-hold | +7.7% |
| QQQ intraday-only, honest costs | +0.8% |
What actually went live: five simple daily rotation sleeves from the corrected board — minus two top performers that were the same credit trade as #1 in different clothes (the one-bet-six-hats lesson, applied). All intraday strategies retired; with them went the minute-by-minute crons, the 15:55 liquidation race, most of the settlement risk, and the entire timeout bug class. The new architecture is one deterministic script, once a day at 09:35, seven liquid ETFs, every failure mode mapped to “hold and alert.” Sized at a 50% pilot with a pre-registered tripwire: the untouched 2024–2025 window runs once, and any sleeve that fails there auto-demotes to cash.
The book's job is to survive being wrong; the research pipeline's job is to find out.
What ~310 strategies taught me
- The benchmark is undefeated. Three AIs, real APIs, ~310 strategies — and “buy QQQ, do nothing” beat almost everything after honest costs. Any pitch that doesn't show you its benchmark is hiding the body.
- Leverage isn't alpha. Every raw-return “winner” in the 40-sweep was 2×/3× leverage: same skill (zero), more risk.
- Your edge might be your data feed. If it doesn't exist on the feed you trade from, it doesn't exist.
- One day of look-ahead was worth six points. Backtests must model when you could have known, not when it happened. The market pays clairvoyants extremely well — which is how you know they're fake.
- The best of 250 garbage strategies looks like genius. Sweeping widely and keeping winners isn't research; it's a lottery with extra steps.
- Diversification can be cosplay. Six sleeves correlated at 0.95 are one bet. Count risk units, not strategies.
- The boring rules are the deadly ones. Nobody models settlement mechanics until the plumbing models you. Learn what a Good-Faith Violation is before your broker teaches you.
- No LLM in the order path. Agents research, write code, audit each other. Deterministic code talks to the broker.
- Adversarial AI review actually works. Builder + independent auditor with reproduction rights caught a missing benchmark, a feed artifact, a clairvoyance bug, an impossible win rate, and a burned holdout. Every catch came from re-running numbers, not reading prose.
Try this at home (the starter kit)
The minimum stack, all of it cheap: a Robinhood agentic account — it's a separate cash account, and expect the investor-profile gate at trade #2 (their developer docs are the entry point) · Alpaca's free IEX data tier, which powered every backtest here · a free FRED API key for macro · one AI to build · and a different AI to audit — same-model self-review goes soft. Make the auditor reproduce numbers, not read reports.
House rules we'd actually defend:
- Money you can lose without changing your life. This is a lab, not a retirement plan.
- Benchmark everything against buy-and-hold and against a dumb 20-day moving average. If you can't beat the dumb stuff, you don't get to run the smart stuff.
- Costs at 3–5 bp per side minimum, computed on the feed you'll actually trade from.
- Pre-register strategies before running them. The holdout window runs once.
- No LLM places orders. Kill-switch file. Daily heartbeat — silence must mean “broken,” never “fine.”
- Cash account? Learn the settlement rules before the settlement rules learn you.
The pilot is live at half size. The honeypot is armed. The untouched 2024–2025 window is the last match in the box, and it gets struck exactly once. I'll report back — including, especially, if the answer stays “you should have just bought QQQ.”
Disclosure: this is research and entertainment, not investment advice. Every number above is a backtest or model comparison on one regime (a violent V-shaped half of 2026), not live performance, and nothing here is a recommendation to buy or sell anything. Leveraged ETFs carry decay and tail risks unsuitable for most investors. Real money was used; the amounts were deliberately small relative to net worth. Platform details (Robinhood agentic accounts, the investor-profile requirement, IEX vs SIP feeds) are accurate as of June 2026. Robinhood links are referral links.
Newsletter
Get the next post by email.
One email when I publish something new. No spam, no fixed schedule, unsubscribe anytime.