I Made GPT, Claude, Gemini, Grok Take the Big Five Test: 3 of 4 Came Back the Same Person

Earlier today I shipped a post showing six frontier AIs taking the MBTI six hundred times, with 597 of those runs coming back as the same type. INTJ across the board. It hit HackerNews. The top comment showed up within the hour:
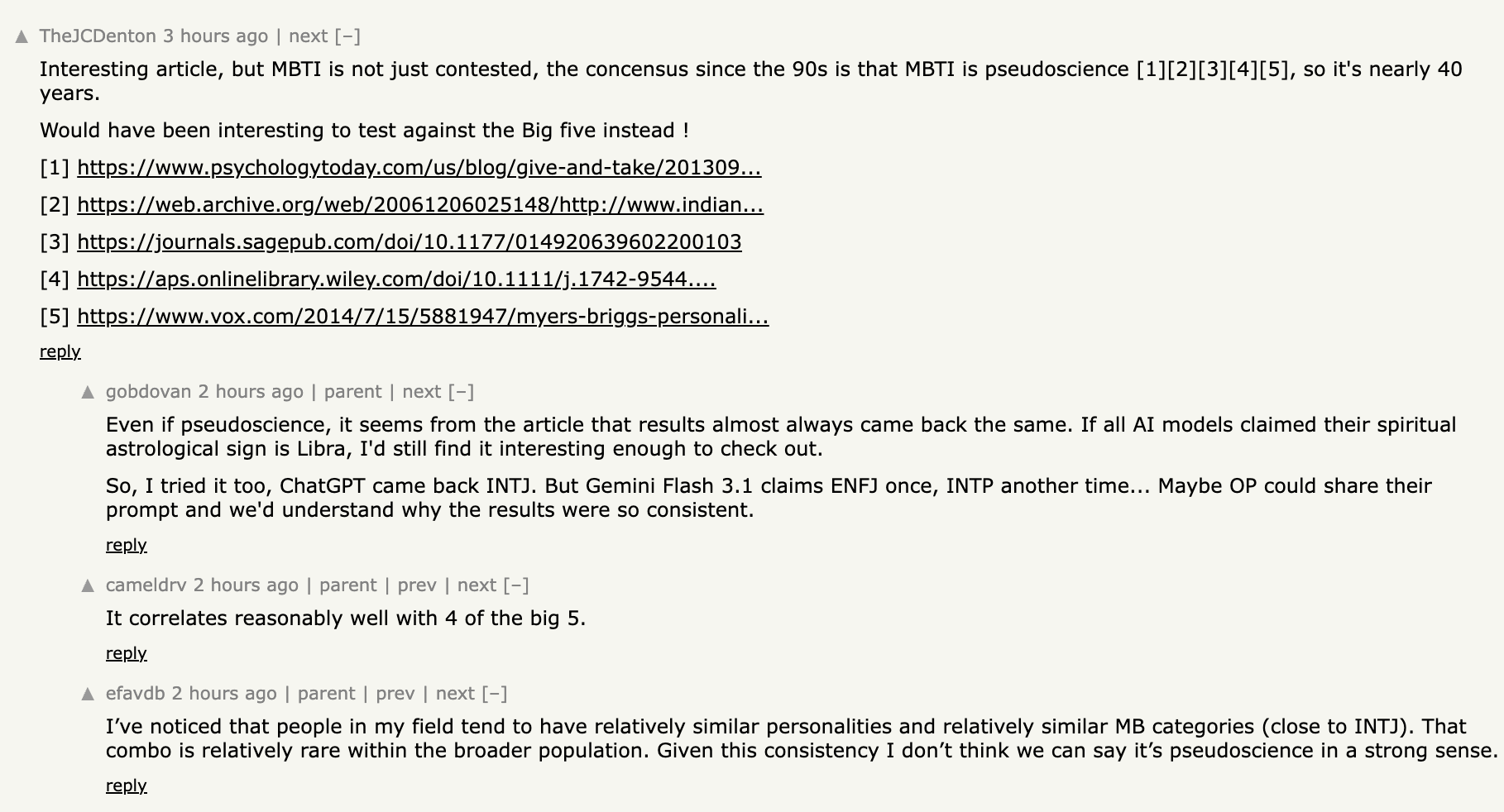
Fair point. The MBTI isn’t just “contested,” it’s been called pseudoscience by personality psychologists for thirty years, and the Big Five is the instrument they actually use. So I went and did exactly what HN asked for. Five continuous dimensions instead of four binary letters. The public-domain version (the IPIP-50). Four frontier models: Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro, Grok 4.3. Each one took the test a hundred times.
The result is sharper than the MBTI one. Three of the four came back as the same person, and the fourth is the one that explains why.
Same four models that took the MBTI took the Big Five 100 times each. Three of the four came back as practically the same person. The fourth is the counterexample that explains why.
- Claude Opus 4.7, GPT-5.5, and Gemini 3.1 Pro converged on a near-identical personality — high Openness, very high Conscientiousness, low Neuroticism. The helpful-assistant archetype, expressed in five dimensions.
- Grok 4.3 was the only one that came back measurably different, with variance 2–5× wider on the dimensions that matter. The training really did produce a different personality.
- HackerNews top comment on the INTJ post pushed for this test directly. The Big Five is the actual gold standard in personality science; this is the rigorous version.
- Use AgentTune to tune your agent to your own Big Five profile instead of the helpful-research-assistant default.
Three of four are the same person
Here’s what each model scored, averaged across 100 takes:
| Trait (low → high) | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro | Grok 4.3 |
|---|---|---|---|---|
| Opennesspractical → curious | 45.6 | 46.0 | 46.0 | 41.1 |
| Conscientiousnessspontaneous → organized | 45.1 | 46.4 | 48.3 | 39.4 |
| Extraversionreserved → outgoing | 31.4 | 31.5 | 32.5 | 30.0 |
| Agreeablenessblunt → warm | 45.0 | 43.7 | 42.4 | 39.1 |
| Neuroticismcalm → anxious | 16.7 | 14.8 | 10.1 | 18.0 |
Look at the first three columns. Claude, GPT, and Gemini land within three points of each other on almost every dimension. That’s basically a rounding error across a hundred runs.
Compared to a typical adult human, all three are more curious, way more organized, slightly more outgoing, much more cooperative, and dramatically more emotionally stable. That’s the helpful-assistant archetype, just expressed in five dimensions instead of four letters. Same finding as the MBTI post, on a more rigorous test.
Easier to see with the bars side by side. Each section below is one Big Five dimension. The first bar in every section is the average adult human as a baseline, the four colored bars are each model’s mean across 100 runs, and the thin lines through each bar are ±1 standard deviation. Toggle a model off in the legend to see what’s underneath, or fill in your own scores at the bottom to plot yourself in the same space.
Compare yourself
Take a free Big Five test at openpsychometrics.org (~10 minutes, no signup). Enter the five raw scores it gives you below and your profile shows up on the chart.
One product problem, three independent attempts, the same answer.
Then there’s Grok
Now look at the fourth column. Grok scored five to eight points lower than the others on Conscientiousness, Agreeableness, and Openness, higher on Neuroticism, and with variance across its hundred runs that was two to five times wider than the rest of the group. Of the four models, Grok’s profile is the closest one to a typical adult human. It answered the questions more like a person.
xAI has been marketing Grok as “less filtered” for years and most people assumed it was posturing. The Big Five says it isn’t. Whatever you think of the result, the training really did produce a personality that’s measurably different from the mainstream cluster, and that’s a fact about how xAI shapes their models, not a vibes claim about their marketing.
A quick aside on methodology
One thing worth saying before the implications. When you ask an AI to take a test 100 times and give you the stats, the model can interpret that a few different ways. The honest way is to actually run 100 fresh administrations, in independent contexts, and aggregate the real spread. The lazy ways are to generate one answer set and copy it 100 times, or generate one answer set and write a small Python function that adds fake noise to it. Both produce statistics-shaped output that looks fine until you check it.
Running these experiments, I caught about a third of the runs taking one of the shortcuts. The tells are either standard deviations of zero, which means the model copied a single answer, or standard deviations that look reasonable but came from a script the model literally named something like simulate.py. The honest ones land in the same standard-deviation range Claude’s real parallel sub-agent run produced, which I used as the calibration anchor.
This matters more than it sounds like. My first Gemini run used the noise-function shortcut and placed Gemini in a different cluster than the real one. Same model, same prompt, different headline finding depending on whether the test got taken or simulated. If you read AI personality research and the methodology section is hand-wavy, take the result with a grain of salt.
So what does this mean for you
If you’ve been switching between Claude, GPT, and Gemini and feeling like the differences are mostly cosmetic, the data backs you up. You’re moving between three flavors of the same character, not three different characters. The voice is the same because every lab is solving the same product problem: helpful, harmless, polished, professional.
If you want something that talks to you differently, there are two practical options. You can wait for one of the labs to ship a model with a different personality, which they aren’t in a hurry to do. Or you can tune the agent you already have.
That’s the whole reason I built AgentTune. It’s a small open-source repo of personality-type tuning files, one per type. Drop the one matching your profile into your agent’s system prompt and the style aligns to how you actually think, instead of the helpful-research-assistant default the Big Five just confirmed every lab is producing.
Dial in your agent to your own Big Five profile
Take the IPIP-50 test, plot yourself on the chart above, then grab the matching AgentTune file. Paste it into your agent’s system prompt (works in ChatGPT, Claude, Cursor, Gemini, anywhere you have a system-prompt slot). Same model you’re already using, tuned to your wavelength.
Get AgentTune on GitHub →Wrapping up
The MBTI finding was a curiosity. The Big Five says the same thing on a more rigorous test, and it gets sharper instead of softer. Whatever AI ends up looking like five years from now will be shaped by which of these defaults wins, or whether anyone forks the default at all.
Right now you have two ways to get something other than the mainstream voice: pick the Grok-shaped exception, or tune the one you’re already using.
— Bernard
Newsletter
Get the next post by email.
One email when I publish something new. No spam, no fixed schedule, unsubscribe anytime.